Simple hash table
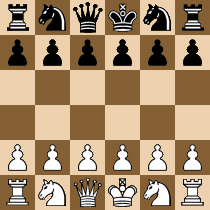
If the engine has the chess position in its memory (or other storage) along with the believed best move, it can just look up this information very quickly and simply output the move. This is actually how many people think chess programs work all the time (or even how human players play!) - that they just know all the positions and can also memorize the best move for each one of them. The problem is obviously that the number of possible chess positions is so astronomical (it's estimated to be about 1050; there is approximately as many atoms in Earth), that it's impossible there would be anything capable of holding such number of positions in some kind of memory.But it's not that crazy idea after all. It's only applicable to the game opening, that means roughly some first 5 to 15 moves of the game. Imagine that the initial position for the chess game has been seen billions of times and millions of players coped with the task to pick one of the 20 possible moves in the initial position (see the picture).

Initial position in chess. There are 20 possible moves for white: 2 moves for each pawn (they go 1 or 2 fields up front) and 2 moves for each knight. Pawn to e4 and pawn to d4 are the most favorite moves. Pawn to c4 and knight to f3 are also played. Other moves are played very rarely.
So the "chess mankind" built up experience in what first move to play (here you can find a very interesting statistical analysis on the first few moves played over time). And so there are 2 most favorite first moves (namely pawn to e4 or pawn to d4) that proved to be good by millions of games. Game opening knowledge (aka opening theory) applies to second and further moves in the game. But with every next move it's more and more likely that a position will come up that is no longer known to the opening theory. So even if the player knows the opening theory perfectly (computer might), he/she/it really needs to start thinking at this point, a simple knowledge of the opening theory won't do.
The knowledge of chess openings built over centuries was further improved by computers. As with many other things in chess, the principle (i.e. plainly using memory) here is the same for human players as for computers - even though the capabilities differ hugely. It's true that humans might memorize the opening positions based on the last move(s) rather than on the actual setting of the pieces, but it is still just a another type of memory after all.
It's quite easy to implement and use opening database (aka opening book) in your chess engine, but it's important that the opening database is harmonized with the engine play style when the game turns into a position that is no longer in the database and another approach needs to be used -
a real computation. For example, your engine might not like openings where you sacrifice a pawn. Even though you may have opportunity for an offensive play in such positions, you need to know the long term strategy. And "knowing the long term strategy" is not something which is typically mastered by chess engines (it is typically a way easier and more natural for a human player to learn what strategy a particular opening needs than it is for a chess engine). What is likely to happen in the given example with the sacrificed pawn is that the engine would reconcile with losing one pawn and it wouldn't try to strengthen the position well enough. This was also the case with Ken Thopson's famous Belle before he realized this opening/middle game style disharmony and started to prune Belle's opening database. The situation is slightly different with human players, but they also need to choose their openings according to their play style in the middle game.
The Polyglot format
There as an open source format for opening books called the polyglot format. It basically defines a hash table, where it leverages a technique called Zobrist hashing. We can visualize the opening book like this:
Each position diagram along with the connected moves represents one entry in the opening book. The cryptic number on top of the diagram is the hash value of the position (these are actual data from the polyglot format as you can check here). Positions are recognized by their hash values because that way it's very fast to look them up. Interestingly, the Zobrist hash function used in Polyglot, that maps positions to 64 bit values, is considered so well discriminating, that the possibility of hash collision (i.e. getting the same hash value for two different positions) is not taken into account (!). Under each hash value we can see the corresponding position in the picture - this is just for our convenience to see what positions are represented by the entries - the position itself is not stored in the database. Each entry is associated with one or more moves that are considered to be good moves in the given position. In fact the believed quality of each move can also be specified in a Polyglot opening book for each of the moves so that the engine can choose always the believed strongest (or the weakest) continuation for example if this is asked for. Beside this static believed quality of the move a dynamically changing measure of quality of the move can also be recorded in the Polyglot book. This will be based on the results of games when the respective move is chosen by the engine.
Even though one position leads to the other (the 4 positions in the picture for example follow one another when the appropriate move is played), it doesn't really matter and this relation is not explicitly captured in the opening book. When the book is used for a given position, the engine just calculates the hash value and looks up the position in the book. This will repeat again for next position without the need for information about the previous look up.
As we could see, keeping all positions in memory is not feasible, but to keep relative small number of positions in an opening book if beneficial. As long as the engine can use an opening book, there is no risk of bad moves (assuming the opening book is good as most of them are) and the play is blazing fast, even for computers.
Retrograde analysis
Whereas the opening books can only be used for game openings, retrograde analysis is applicable for the opposite phase of the chess game - for the endgame. First let's clarify the term retrograde analysis. In somewhat broader (and actually correct) sense the retrograde analysis means analysis of the position based on what happened before - what moves led to this position, what pieces moved etc. Here I cannot fail to mention The Chess Mysteries of the Arabian Knights and The Chess Mysteries of Sherlock Holmes by Raymond Smullyan - absolutely fascinating collections of unusual chess riddles based on retrograde analysis.In the context of chess endgames the retrograde analysis is a special means to create a database of all possible positions within certain endgames with just few pieces (for example king and a rook against king and a knight) and their respective perfect moves. Perfect moves provably lead to the shortest win for positions that are won, defend draw if the position is drawn or advert loss as long as possible when the position is lost. This is in contrast to the opening databases which store only believed best moves - their quality is based on various things: computation, experience, analysis; but there is no prove that they are really the best moves.
Endgame databases are called endgame tablebases and are constructed by finding out all positions that are trivially won, lost or drawn and then by moving backwards to find out which positions lead to those found in the previous step. This continues recursively until perfect moves are found for all positions within the given endgame.
In more detail it works as follows:
- Start with a trivial endgame. King vs. king is even too simple, because that's always a draw. Pick something different. Say king vs. king and the queen. This is, except of very rare cases when the king can just take the queen or is in stalemate - both of which are draws - a win for the queen side.
- Iterate over all possible positions within this endgame. There is actually a very low number of these positions in our example endgame with kings and a queen (relatively compared to how many operations a computer can execute within a second). The upper estimate is 64 x 63 x 62 x 2 = 499,968.
- When iterating, it's very simple to recognize positions that are either already a draw or lead to the draw trivially (king takes the queen) or are check mate. Mark them drawn(0) = stalemate, drawn(1) = king takes queen, or lost(0) = check mate.
- In the next iteration, find positions where one of the moves leads to a check mate (i.e. to a position marked as lost(0) in the previous iteration). Mark these positions 'won(1)' (and possibly save the move that leads to 'lost(0)' along with this mark).
- In the next iteration, find positions where the side without queen is to move, and ALL of its moves lead to positions marked as 'won(1)'. Mark those as 'lost(2)'. In the generic case when all moves lead to a loss, pick the move that would postpone the check mate as long as possible (in other words, find maximal n among 'lost(n)' marks).
- Repeat iterations until you mark all the positions. In case of this endgame you will finish after about 21 iterations (the longest forced win is in 10 moves - see Wikipedia).
- In other endgames you can encounter positions that will never be marked this way. In that case there will be an iteration that wouldn't contribute with any marking. After this iteration, you can stop and mark the rest of the positions as draws. This case is discussed below in more detail.
In the previous example we considered endgame with kings and a queen. But other endgames are more tricky. First beware that in most of the endgames both sides can win. Also, some draws might never be labeled within any iteration. I will explain the reason for that.
In this algorithm, we are actually dealing with a directed graph, where nodes are positions and vertices are moves that lead from one position to another. The situation is visualized in the following picture:

The picture reflects a situation where we are in the 9th iteration since we can see marked positions with 0,1,2...7 and in each iteration the number increases by one. During this 9th iteration we come across the node denoted with ?8. It's a lost position since all moves lead to won positions (but won for the opposite side). It'll be marked with 8, since the defeat can be at best deferred by moving to a won position marked with 7. Let's move on to 10th iteration. We encounter the node denoted by ?9 in the middle of the picture. Even though most of the moves lose the game, there is a winning move that leads to a lost position for the opposite side (red 8). Therefore it's a won position and will be marked with 9. The situation is similar at the node marked with ?9 at the top of the picture. The difference is that there is a move leading to a position that is yet to be marked. But all positions won in 8 and less moves (actually 7, winning positions are always odd) have already been marked, so the move leading to the unknown node cannot be better than the one leading to red 8. Therefore the ?9 node at the top is also won and will become green 9. The rest of the white nodes denoted by just ? will never be marked in such manner as mentioned earlier. These will emerge as the nodes that haven't been marked yet even after an iteration that has not contributed with any marking. Even though some of them lead to won positions (and therefore the corresponding moves lose the game), all of them lead to some other nodes labeled with '?'. In fact these are all drawn positions. This would be the case of a simple threefold repetition (perpetual check for instance) or maybe completely blocked positions (which can eventually end in a 50 move draw). They can also be more complex positions that can lead to capturing moves and eventually to a trivial draw. These would emerge as unmarked nodes that connect to other unmarked nodes or to green ones. The only way not to lose (i.e. not to skip to a green node) is to stick with the unmarked ones and go from one to another by playing the corresponding moves.
Now let's again see what happens when a tablebase is being created for some more difficult endgame - say king and a rook versus king and a knight - and you do a capturing move. You will fall out of the current endgame and end up in another one (i.e. king vs king and knight if you happen to capture the rook). This is the situation hinted with the pink node in the previous picture. When creating endgame tablebase for a certain endgame, you need to already have tablebases for all endgames that can emerge from this one. Obviously these are all endgames where a piece is missing (i.e. king takes rook), but the situation gets complicated when pawns are present. They can promote to four different pieces (rook, knight, bishop and queen). We thought about the positions and moves within an endgame as of
a directed graph. Now there is another directed graph emerging - namely the graph of the endgames themselves - it's given in the following picture:

Getting back to the previous graph, yellow nodes are endgames that are draws due to insufficient material. A single pink node - KB kb - is automatically a draw for the same reason if the bishops occupy fields of the same color, but in all but rarely cases it's a draw even when they don't. Green nodes are endgame where one side has a bigger chance to win. Blue nodes mark endgames where the chances are exactly the same for both sides. When creating a database for an endgame, you need to already have all complete tablebases that the corresponding node directly leads to. For example, if you want to create a tablebase for KQ kp, you need to have all of the following tablebases ready: KQ kq, KQ kr, KQ kn, KQ kb, KP k.

Normalizing mirrored endgames. For example any position in the KP kr endgame can be transformed to an equivalent position in the KR kp endgame by flipping the board, color of the pieces and a side to move. The picture shows a position on the left from KP kr endgame. Let's assume black is to play. This position is equivalent to the one on the right side, where white is to play. As a general rule we can for example say that all endgames where white has weaker pieces will be mirrored to the one where it has stronger ones, but not the other way around (as in the example - the left position is transformed to the one on the right side).
History and impact of endgame tablebases
The possibility of endgame tablebases was already shown by the work of Ernst Zermelo (founder of the set theory by the way, a very important person for mathematics) in 1913, but real endgame tablebases were not implemented until 70's. In 1977 Ken Thompson (again him!) stirred excitement when he bet with at the time reigning US chess champion Walter Browne. Thompson claimed that his tablebase program can defer the endgame king and rook vs. king and queen for more than 50 moves for the side with the rook (this would mean a 50 move draw in a real game). Indeed it could and Browne lost 50 bucks. He eventually won them back in a re-match (for more info see this interview transcript with Ken Thompson). These bets showed that some of the endgames are far more tricky than it seemed and that they can be mastered better by computers than by humans.
But this was by no means end of the story. Thompson started to implement other, more difficult endgames with 5 pieces on the board. One of the most interesting one was king and two bishops vs. king and knight. For centuries it was believed that this endgame is a draw whenever the side with the knight can reach the so called Kling-Horowitz position:

Thompson's program showed that even this position - as almost any other position in this endgame - is lost for the side with the knight. It also showed that the longest series of moves leading to capturing of the knight is 66 (full-)moves long. This would be technically a draw due to the 50-move rule. But does that mean the rules should be changed? White can prevail eventually, right?
Chess masters not only believed that Kling-Horowitz position is a draw, but they thought they were able to reason about why it was so. So when this was proved wrong, chess players also thought computers can show them why and believed that a generic strategy can be articulated as to how to win this endgame. They were, again, wrong. Computer can play the endgame against you as many times you want and will beat you every single time, but that doesn't mean you can infer "a winning strategy". In the case of breaking the Kling-Horowitz position, some of the moves don't seem to make much sense and they definitely don't form a unified strategy. Remember that the tablebase is a result of a brute force computation at its best and when computer plays an endgame it just looks the moves up, no more, no less. No strategy.
This impossibility of inferring a strategy from computer moves led to desillusion and frustration about the tablebases and computer chess in general. Some even claimed that computer chess had ruined chess, and if not already, they would eventually. I don't think it's true even though I understand such opinions. Also note that once again computer was asked to solve a problem and it did. Only the way it did it was unexpected and less revealing than it was desired.
The storage space requirements are indeed high. On the other hand they will be much much higher if the data were not densely compressed. For example, let's try to compute the number of positions for all 5 piece endgames. The upper bound would be
110 x 64 x 63 x 62 x 61 x 60 x 2 = 201,287,116,800
110 stands for 110 types of endgames (this already takes into account normalization of mirrored endgames - see above), the product of numbers from 64 to 60 accounts for different pieces being put on the board on different fields. Finally we multiply by 2 to account for different sides to move. Many of these positions are invalid (kings are next to each other or the side to move can take opposing king). It's questionable how many invalid positions there can be. I will assume there is 1 invalid position for 1 valid one. This would mean about 100 billions positions are covered by 7GB of data, which would mean one byte would cover roughly 13 positions. This is pretty impressive.

 In KQ k endgame 8 different positions can be normalized and treated as one, because they can be transformed from one to another using 3 symmetries: symmetry around vertical and horizontal axis and around one of the diagonals of the board. We can also get the same 8 positions using any one of these symmetries and rotation.
In KQ k endgame 8 different positions can be normalized and treated as one, because they can be transformed from one to another using 3 symmetries: symmetry around vertical and horizontal axis and around one of the diagonals of the board. We can also get the same 8 positions using any one of these symmetries and rotation.
But this was by no means end of the story. Thompson started to implement other, more difficult endgames with 5 pieces on the board. One of the most interesting one was king and two bishops vs. king and knight. For centuries it was believed that this endgame is a draw whenever the side with the knight can reach the so called Kling-Horowitz position:
Kling-Horowitz position - black believed to reach a position where it can defend the draw
Thompson's program showed that even this position - as almost any other position in this endgame - is lost for the side with the knight. It also showed that the longest series of moves leading to capturing of the knight is 66 (full-)moves long. This would be technically a draw due to the 50-move rule. But does that mean the rules should be changed? White can prevail eventually, right?
Chess masters not only believed that Kling-Horowitz position is a draw, but they thought they were able to reason about why it was so. So when this was proved wrong, chess players also thought computers can show them why and believed that a generic strategy can be articulated as to how to win this endgame. They were, again, wrong. Computer can play the endgame against you as many times you want and will beat you every single time, but that doesn't mean you can infer "a winning strategy". In the case of breaking the Kling-Horowitz position, some of the moves don't seem to make much sense and they definitely don't form a unified strategy. Remember that the tablebase is a result of a brute force computation at its best and when computer plays an endgame it just looks the moves up, no more, no less. No strategy.
This impossibility of inferring a strategy from computer moves led to desillusion and frustration about the tablebases and computer chess in general. Some even claimed that computer chess had ruined chess, and if not already, they would eventually. I don't think it's true even though I understand such opinions. Also note that once again computer was asked to solve a problem and it did. Only the way it did it was unexpected and less revealing than it was desired.
Endgame tablebases implementation
Work with the KBB kn endgame was already done by Thompson in the 70's. More complex tablebases with more pieces on board have been created by then. All 5 and 6 piece endgames have been analyzed, some of the 7 piece endgames as well. But you may still wonder why the progress has been so little. Well, it only appears as a little progress, because the number of positions with any extra piece increases very steeply. The storage requirements are also huge. For example, this site offers endgame databases. It claims they are in a new, storage space saving format. Still, if you want to download all 6 piece databases in a densely compressed format, be prepared to allot 1146 GB of your hard drive(!). In contrast, all 5 piece endgames are only about 7 GB. This already shows how the complexity grows from 5 to 6 pieces endgames.The storage space requirements are indeed high. On the other hand they will be much much higher if the data were not densely compressed. For example, let's try to compute the number of positions for all 5 piece endgames. The upper bound would be
110 x 64 x 63 x 62 x 61 x 60 x 2 = 201,287,116,800
110 stands for 110 types of endgames (this already takes into account normalization of mirrored endgames - see above), the product of numbers from 64 to 60 accounts for different pieces being put on the board on different fields. Finally we multiply by 2 to account for different sides to move. Many of these positions are invalid (kings are next to each other or the side to move can take opposing king). It's questionable how many invalid positions there can be. I will assume there is 1 invalid position for 1 valid one. This would mean about 100 billions positions are covered by 7GB of data, which would mean one byte would cover roughly 13 positions. This is pretty impressive.
We already saw that we can save data if we omit mirrored endgames. The next most straightforward way to compress the data is to leverage mirroring of the positions themselves. If we consider KQ k endgame for now, we can take advantage of three different symmetries. This is shown in the following picture:
The problem here is that some of the endgames don't allow for such transformations. Most importantly pawn endgames (also beware that pawn-less endgames are not frequent in real games) forbid all transformations but the rotation around vertical axis. Positions where a castle is still possible forbid even this one (but unlike pawns you can treat them as exceptional cases - they are in fact ignored in some of the real world endgame tablebases).
Another question you may ask is how to represent the tablebase entry. Encoding each and every position one by one would be just wasting. The approach would be to skip this explicit encoding altogether. All you need is to come with some ordering of the positions within the endgame and just encode the marks (i.e. won(n)/lost(n)/drawn) and the moves. You will know where the entry for a given position is just by calculating its order in the database.
Furthermore, you can skip encoding of the moves as well because you can infer them on the fly. If an entry says won(n), you would generate all positions that can be reached directly from won(n). You would then look them up as well and you will find one or more lost(n-1). The corresponding moves that lead to lost(n-1) are the perfect moves you were looking for.
The last question is how to encode the marks. You need 2 bits for the type (drawn/won/lost) and the rest for the numbering. There are multiple approaches as to how encode the numbers:
Depth to Mate - this is basically what I have been describing so far - so the number in won(n) would simply be encoded as n.
Depth to Conversion - this is number of moves (or plies to be correct*) to position with changed material - either after a capturing or pawn promoting move.
Depth to Zeroing - this is the number of moves to a pawn push or a capture
There are also other approaches. Advantage of the first one on our list is that it's very straightforward. Advantage of the others is that the numbers can be smaller and therefore it can further save some bits for storing an entry.
As we could see we can only do with storing the type (won/lost/drawn) and possibly a small number indicating - one way or the other - how long it will take to reach a win or to postpone a loss. We can also take advantage of some of the position symmetries. This would already save a lot of storage space, but it wouldn't cover 13 positions in one byte as computed in our previous example. So other, more advanced techniques to compress the tablebases are also used in current tablebase formats. The most favorite ones are Nalimov, Gaviota and Scorpio and there are many others.
This, however long, was just a quick overview of the endgame tablebases. They are now ubiquitous and commonly used by chess engines. However, keep in mind that they are used only for a small fraction of positions, namely for endgames with small number of pieces.
* Throughout this article I mostly use the word move to mean ply. Ply is a single move done by either side, whereas move or rather full move is defined as the pair of moves done by both sides. I hope that the actual meaning of the word move can always be correctly inferred from the context.
Furthermore, you can skip encoding of the moves as well because you can infer them on the fly. If an entry says won(n), you would generate all positions that can be reached directly from won(n). You would then look them up as well and you will find one or more lost(n-1). The corresponding moves that lead to lost(n-1) are the perfect moves you were looking for.
The last question is how to encode the marks. You need 2 bits for the type (drawn/won/lost) and the rest for the numbering. There are multiple approaches as to how encode the numbers:
Depth to Mate - this is basically what I have been describing so far - so the number in won(n) would simply be encoded as n.
Depth to Conversion - this is number of moves (or plies to be correct*) to position with changed material - either after a capturing or pawn promoting move.
Depth to Zeroing - this is the number of moves to a pawn push or a capture
There are also other approaches. Advantage of the first one on our list is that it's very straightforward. Advantage of the others is that the numbers can be smaller and therefore it can further save some bits for storing an entry.
As we could see we can only do with storing the type (won/lost/drawn) and possibly a small number indicating - one way or the other - how long it will take to reach a win or to postpone a loss. We can also take advantage of some of the position symmetries. This would already save a lot of storage space, but it wouldn't cover 13 positions in one byte as computed in our previous example. So other, more advanced techniques to compress the tablebases are also used in current tablebase formats. The most favorite ones are Nalimov, Gaviota and Scorpio and there are many others.
This, however long, was just a quick overview of the endgame tablebases. They are now ubiquitous and commonly used by chess engines. However, keep in mind that they are used only for a small fraction of positions, namely for endgames with small number of pieces.
* Throughout this article I mostly use the word move to mean ply. Ply is a single move done by either side, whereas move or rather full move is defined as the pair of moves done by both sides. I hope that the actual meaning of the word move can always be correctly inferred from the context.
Computation based on game state tree
I could also use the title "The mainstream approach" as this one is really the most widely used. It's not only used in the middle game, the only phase of chess game we haven't covered yet. It's also used in the game opening, either because the engine doesn't have an opening database at hand or because it just happens to be validating one against its play style. On the other end of the spectrum, a position with even 10 pieces can already be considered an endgame, however we are still far away from having it covered by an endgame tablebase. So again, the standard computation is used.The game state tree
A fundamental structure here is the game state tree. It's common to all types of move based games and tree themselves are a cornerstone to all sorts of algorithms. One such tree representing chess game states is depicted below along with the starting position.

Imagine that the starting position is represented by the root node at the top, the branches (lines connecting the nodes) represent the moves and the nodes below the root represent positions that arise from the positions above them. The nodes at the bottom are called leaves. Number of levels below the root is called depth of the tree (here it is 2) and says how many plies from the starting position (see above for definition of ply) can be calculated. The moves represented by the branches are given next to them in the algebraic notation. For example, Qxg5+ means queen moves and takes on g5 (field on g file, 5th rank) and checks the (white) king.
If it weren't for the node at the right, all of the non-leaf nodes would have 3 descendant nodes in this idealized example. This property of the tree is called the branching factor of the tree (would have been equal to 3 here then). Middle game state trees have branching factor of 38 on average (meaning there are 38 possible moves in a middle game position on average). We will see that minimizing the effective branching factor (by ignoring some of the nodes) is essentially the main goal in the whole chess programming. This can clearly be seen if we want to calculate how many leaves need to be processed. We will use this formula:
l = bd
where l is the number of leaves, b is the effective branching factor and d is the depth of the tree (aka depth of the computation). We can only process some maximum number of leaves within a period of time and we definitely want to maximize d, since the bigger d, the better insight into the position our engine can get. Therefore we need to minimize the branching factor. This formula for l is basically just an exponential function. Exponential functions are known to increase very steeply. For instance, if we stick with the average branching factor of 38 from a real world middle game and we only want to search a tree of depth 8, which by the way is far from being good, we would have to process
4,347,792,138,496 leaves !
Even if we are able to process 100 millions leaves per second (believe me, this is very good), we would still need over 12 hours for the whole computation (!). This steep increase in number of leaves (i.e. positions) is sometimes referred to as the exponential explosion and it really is the number one reason why playing chess is not that easy task even for computers.
The game state tree needs to be processed during the computation even if it means skipping or ignoring some of the nodes. Again, this is no different from the way human players think. Consciously or not, more precisely or less, intuitively or organized, human players also process the game state tree in their heads. But how would they do that? In which order? What do they actually do when they process a given node or a leaf? How do they assess them? And how do these assessments help them in choosing the best move from the starting position?
Let's get back to computers The computation is basically as follows:
- the tree is processed depth first. This means the left side of the tree is first searched down to the leftmost leaf. Then its sibling leaves are searched from left to right. Then siblings of their parent node are searched, but whenever a new node is encountered all of its children are searched down to the leaves. Everything is left to right. In our example this would mean the following order of the nodes: Nf7, Kxf7, Dh4+, Vh4+, Dg5+, Dxg5+, Kf8, Kh7, Dxh8+, Kxh8
- the tree is processed until some fixed depth. When the leaves are reached, their respective positions are evaluated. Evaluation of positions is a very broad and complex topic, but for know we can assume evaluation based merely on material, where each piece type is given a relative value (see the possible values here) and the values of all pieces summed together for both sides are compared. For the starting/root position in our example this would mean:
- white: 1 (pawn) + 3 (knight) + 9 (queen) = 13
- black: 5 (rook) + 9 (queen) = 14
- this means black is better off by one (as if by one pawn)
- processing the tree in the right order is obviously not good enough. The best move from the starting position needs to be found. In order to that, nodes are evaluated based on evaluation of their children nodes. This goes from parents of the leaves up to the first level of nodes, namely the children of the root node. Here the node with the highest value wins and the respective move is then played. Voilà! This recursive evaluation based on nodes' children is the basis of the algorithm called mini-max. I will cover mini-max in the next post in more depth. Mini-max is further improved by related algorithm called alpha-beta pruning.
This sounds easy, right? As usual, it's just very idealized picture though! Here I will try to sum up why the previous bullets are not strictly correct in the real world scenario
- the depth first search is somewhat combined (at least you can look at it that way) with breadth first search within a technique called iterative deepening algorithm
- there is also no fixed depth search when iterative deepening algorithm (aka IDA) is used. Fixed depth is actually not desired in the real world scenario, because we don't know how many nodes there are for a tree of a given depth and therefore we don't know how long the computation will take (IDA fixes this among other things). Fixed depth is also not desired because we want to spend more time on searching more interesting paths in the tree that correspond, for example, to captures, checks, promotions, check mate threads and so on
- the term "depth of the tree" also depends on the context. In the real world, the tree is searched quite exhaustively until some depth (d1). Then only relatively small number of nodes are searched under every node at depth d1 - usually only capturing moves, checks and promotions. This is called quiescence search, because it really searches for quiescent positions. This goes until some depth d2 > d1. Furthermore, quiescence search is usually combined with static exchange evaluation (depth d3). Only then the true leaves are reached. The position might be evaluated at either of these d1-d3 depths. Some of the evaluation criteria are also incrementally updated at each node at the tree, like the material balance. Here we see that we gradually descent from the exhaustive search near the root to more and more selective search down the tree. Also, as we go down the tree, more time is spent on evaluating the positions
- mini-max and even more importantly alpha-beta pruning are essential to the computation. Nevertheless they are combined with yet other techniques (hash tables, null-moves, killer-moves, move-ordering and others) that can further change the way how the tree is searched
Summary
Here I wanted to present a broader picture before a delve into the game state tree search in more depth. We have seen that computers can play chess in at least three essentially different ways. They can look up the position in their opening books. Moves in opening books are based either on experience built up by human players during a long time or are discovered by computers themselves and proved to be good moves in real world games. Even though opening books can store many millions of moves, they can only cover first several moves of the game. When a position is in the opening book, the best believed move is looked up easily and fast, since opening books are actually nothing than simple hash tables.
Endgames tablebases can be used for looking up the best moves in endgames with few pieces on the board (less than 8). They require large storage space even though the data are very neatly compressed in them. The best move can also be looked up very fast. An endgame tablebase can be looked at as a graph of all positions within an endgame, connected by moves. Endgame types themselves form acyclic graph. The important difference between endgame tablebases and other approaches is that endgame tablebases store perfect moves, moves that provably lead to a win if possible or postpone the loss as long as possible if the position is lost.
When neither opening books nor endgame tablebases can be used, calculation based on searching the game state tree is used - this is actually most of the time ;-) Such approach inherently face what is called an exponential explosion - a steep increase of the number of nodes with increasing depth of the tree. Game state tree is searched more exhaustively near its root and more selectively near its leaves. At leaves or above them the positions are evaluated, The most basic, but still not sufficient evaluation is based only on the material balance. The essential algorithms that drive the search of the tree and eventually determine the best move are mini-max algorithm and alpha-beta pruning. We will take a closer look at them in the next post.